
Miljoniem no mums mijiedarbība ar AI tērzēšanas robotiem ir kļuvusi par ikdienas rutīnu. Mēs uzdodam jautājumus, idejas par prāta vētru, e -pasta ziņojumiem un dažreiz, iespējams, neapzināti, dalāmies ar sensitīvu informāciju. Ir neizteikta izpratne, ka, izdzēšot tērzēšanu, tā ir pagājusi uz labu. Bet nesenais sākuma tiesas rīkojums, kurā iesaistīts Openai, uzņēmums, kas atrodas aiz Chatgpt, netīšām ir atvilcis aizkaru par šo pieņēmumu. Šī attīstība atklāja realitāti, kas daudziem lietotājiem varētu šķist satraucoša: privātuma ilūzija AI mijiedarbībā vai tērzēšanā.
Šī atklāsme izriet no augstas likmes likumīgas cīņas starp Openai un New York Times. Atpakaļ 2023. gadā The Times iesniedza Autortiesību pārkāpumu tiesas procesu. Izdevējs apgalvoja, ka Openai nelikumīgi izmantoja savu plašo ar autortiesībām aizsargāto rakstu krātuvi, lai apmācītu savus jaudīgos AI modeļus. Juridiskā procesa ietvaros federālā tiesa nesen izdeva plašu direktīvu: Openai ir uz nenoteiktu laiku jāsaglabā katras sarunas žurnāli, ieskaitot tos lietotājus, kuri domāja, ka viņi ir izdzēsuši.
Šokējošā secība: dzēšana nenozīmē
Būtībā nospiežot, ka poga “Dzēst” neliks jūsu tērzēšanai pazust digitālajā ēterī. Nu, tie jums vairs nebūs pieejami, bet viņi atradīsies Openai datu bāzē. Tas ir “Murga” Openai COO, Breda Lightcap, kodols. Tiesas rīkojums prasa, lai Openai būtu saglabāti visi lietotāju tērzēšanas žurnāli un API klienta saturs bez ierobežojuma datuma. Tiesnesis paziņo, ka pasākuma mērķis ir novērst jebkādu iespējamu pierādījumu dzēšanu, kas attiecas uz autortiesību strīdu. Šajā brīdī šķiet svarīgi atcerēties, ka Openai atzina, ka nejauši izdzēsa iespējamos pierādījumus tajā pašā NYT tiesas prāvā.
Džeina Doe, CyberSecure LLP privātuma padomniece, sacīja: “Šī direktīva ir nepieredzēta un nosaka bīstamu precedentu lietotāja autonomijai. VaiUzņēmumiem ir nepieciešami skaidri noteikumi, kas līdzsvara atklāšanai ir nepieciešami ar fundamentālām privātuma tiesībām”Viņi piebilda.
Uz IA orientētā firma aktīvi pārsūdz šo lēmumu. Uzņēmums dedzīgi apgalvo, ka šāds pasūtījums ir būtisks lietotāju privātuma pārkāpums. Tas arī tieši ir pretrunā ar viņu noteiktajām privātuma saistībām. Viņi arī norāda uz milzīgo tehnisko un loģistisko slogu šādu kolosālo datu kopu glabāšanai uz nenoteiktu laiku. Tā ir likumīga sadursme, kas negaidīti ir kļuvusi par “smēķēšanas pistoli”, kas atklāj plašāku AI nozares datu vākšanas praksi un apstrīdi priekšstatu par to, ko “privātais” patiesībā nozīmē ģeneratīvas AI laikmetā.
GitHub galvenais produktu virsnieks Inbal Shani nepiekrīt arī pieejai uz bezgalīgi saglabāt lietotāju mijiedarbības datus ar AI platformām. VaiDati, ko izmanto, lai apmācītu AI, nevajadzētu pārsniegt savu likumīgo vai ētisko glabāšanas laiku, ” Viņa teicaApvidū “Organizācijām ir vajadzīgas automatizētas sistēmas, lai izdzēstu vai anonimizētu datus, it īpaši, ja tās tiek atkārtoti izmantotas vai pārvietotas”Piebilda Šani.
Datu vākšanas realitāte: ciešāk apskatiet, ko apkopo tērzēšanas roboti
Ja Openai tagad ir spiests saglabāt pat “izdzēstas” tērzēšanas sarunas, tas liek jautāt: cik daudz mūsu dati tiek savākti ar šiem AI tērzēšanas robotiem? Lai gan tiesas rīkojums šajā kontekstā ir raksturīgs Openai, tas liek plašāk pārbaudīt nozari.
Saskaņā ar kiberdrošības firmas Surfshark pētījumiem, AI Chatbot datu vākšanas ainava ievērojami atšķiras. Tomēr kopējais attēls liecina par milzīgu apetīti pēc lietotāja informācijas:
- Meta AI: Tiek ziņots, ka visvairāk lietotāju datu apkopo populāros tērzēšanas robotos, apkopojot satriecošos 32 no 35 iespējamiem datu veidiem. Tas ietver tādas kategorijas kā precīza atrašanās vieta, finanšu informācija, veselības un fitnesa dati un citas sensitīvas personas detaļas.
- Google Dvīņi: apkopo 22 unikālus datu tipus, kas ietver arī precīzus atrašanās vietas datus, kontaktinformāciju, lietotāja saturu un meklēšanu un pārlūkošanu vēsturē.
- Chatgpt (Openai): apkopo mazāk veidu salīdzinājumā ar citiem, pie 10 atšķirīgiem datu tipiem. Parasti tie ietver kontaktinformāciju, lietotāja saturu, identifikatorus, lietošanas datus un diagnostiku. Proti, Surfshark analīze liecina, ka ChatGpt izvairās no datu izsekošanas vai trešo personu reklāmas izmantošanas lietotnē.
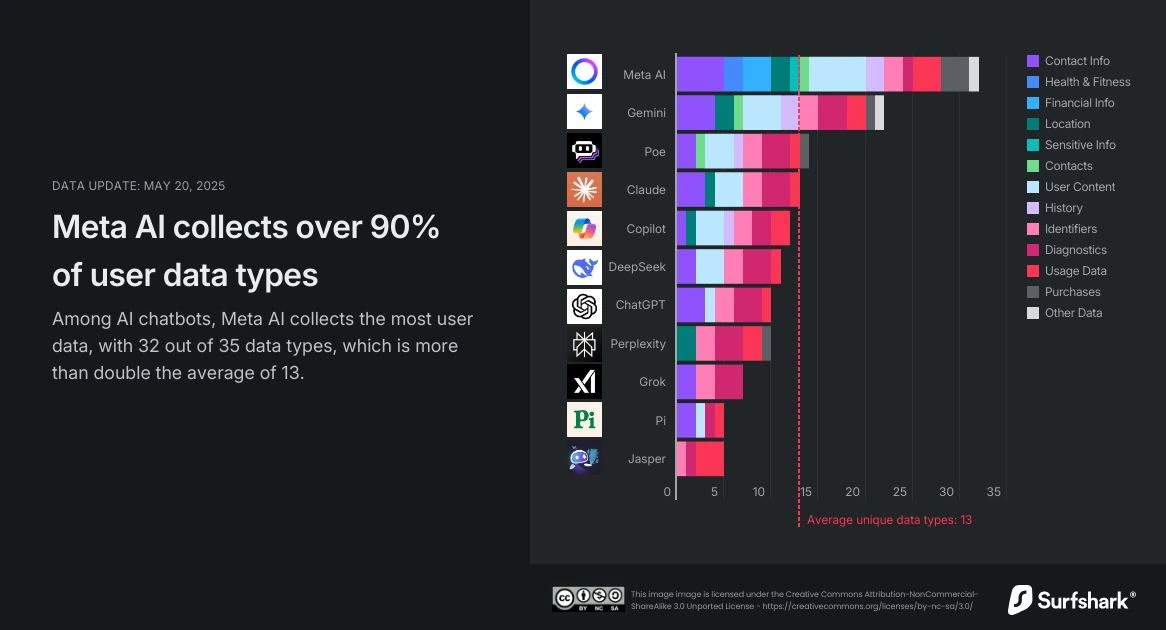
Šis salīdzinājums izceļ kritisko datu vākšanas spektru. Lai gan daži uzņēmumi varētu savākt mazāk, ievērojams ir milzīgais datu apjoms un veids, īpaši sensitīva informācija, ko var saistīt ar jūsu AI mijiedarbību. Regulatori jau pamana šo realitāti. Piemēram, Itālijas privātuma sargsuns nesen iepļaukāja Replika AI ar soda naudu 5 miljonu eiro apmērā par nopietniem GDPR pārkāpumiem, kas saistīti ar lietotāju datiem. Šie gadījumi izceļ globālu virzību uz lielāku atbildību un pārredzamību AI datu apstrādē.
Bīstams precedents: uzticības iznīcināšana un privātuma no jauna definēšana
Openai tiesas rīkojums nosaka bīstamu precedentu ne tikai Openai, bet arī visai AI nozarei. Tas satricina ērtu ilūziju, ka lietotāju sarunas ir īslaicīgas vai patiesi “izdzēstas”. Lietotājiem tas nozīmē, ka jebkura sensitīva informācija, personiskas domas vai privāti jautājumi, kas kopīgi ar AI tērzēšanas robotu, serverī varētu pastāvēt uz nenoteiktu laiku. Tātad tie varētu būt potenciāli pieejami ar likumīgu piespiešanu. Tas varētu izraisīt atvēsinošu efektu, kad lietotāji pašcenzi vai nevēlas iesaistīties AI par jutīgām tēmām, graujot pašu lietderību un uzticoties, ka šo rīku mērķis ir veidot.
Sam Altmana “AI privilēģija”: aicinājums uz konfidencialitāti
Datu kopīgošana ar AI tērzēšanas robotiem, piemēram, Chatgpt, arī varētu mazināt Openai redzējumu par šāda veida platformām. Ņemot vērā šo privātuma ainavu, Openai izpilddirektors Sems Altmans ir paudis pārliecinošu argumentu par to, ko viņš sauc par “AI privilēģiju”. Altmans uzskata, ka mijiedarbība ar AI galu galā jāārstē ar tādu pašu konfidencialitātes un aizsardzības līmeni kā sarunas starp ārstu un pacientu vai advokātu un klientu. Viņš pat ieteica “laulāto privilēģijas” kā piemērotāku analoģiju dažu AI mijiedarbību tuvībai.
Šis jēdziens nav tikai teorētisks; Tā ir tieša reakcija uz jauno realitāti, ko pakļauj tiesas prāva. Altmana aicinājums uz “AI privilēģiju” atspoguļo pieaugošo nozares izpratni, ka pašreizējie juridiskie un ētiskie ietvari ir slikti sagatavoti, lai risinātu unikālos datu privātuma izaicinājumus, ko rada sarunvalodas AI. Viņš cer, ka sabiedrība nekavējoties risina šo jautājumu, atzīstot dziļo ietekmi uz lietotāju uzticību un AI lietderību.
Praktiski soļi lasītāji var veikt tieši tagad
Ņemot vērā šīs atklāsmes, ko jūs varat darīt, lai aizsargātu savu privātumu, mijiedarbojoties ar AI tērzēšanas robotiem?
- Ņemiet vērā sensitīvos datus: izvairieties no ļoti sensitīvas personiskās, finansiālās, veselības vai konfidenciālās informācijas dalīšanās ar jebkuru AI tērzēšanu. Pieņemsim, ka jebko, ko jūs rakstāt, varētu saglabāt.
- Pārbaudiet privātuma politiku (bet paliek skeptiski): uzņēmumiem ir privātuma politika, kas ieskicē datu apstrādi. Tomēr atcerieties, ka tiesas rīkojumi var piespiest datu saglabāšanu, potenciāli ignorējot standarta dzēšanas politiku.
- Izmantojiet “viesu” vai “inkognito” režīmus: ja AI pakalpojums piedāvā pagaidu vai inkognito režīmus (piemēram, Chatgpt “tērzēšanas vēstures un apmācības” pārslēgšana), izmantojiet tos. Tomēr saprotiet, ka “pagaidu” bieži nozīmē “izdzēsti no jūsu redzamās vēstures”, ne vienmēr pastāvīgi izdzēsts no visām aizmugures sistēmām.
- Regulāri pārskatīt konta iestatījumus: periodiski pārbaudiet AI tērzēšanas robota konta iestatījumus, lai iegūtu datu saglabāšanas vai dzēšanas iespējas, un, ja tie ir pieejami, izmantojiet tos.
- Esiet informēts: sekojiet līdzi jaunumiem un privātuma diskusijām par AI. Regulatīvā ainava strauji attīstās.
Nozares, juridiskās un likumdošanas atbildes
Openai tiesas rīkojums neapšaubāmi ir nosūtījis ripples visā AI nozarē. Kaut arī neviens cits nozīmīgs AI uzņēmums nav publiski paziņojis par tūlītējām, tiešām politikas izmaiņām, īpaši reaģējot uz šo rīkojumu (ārpus esošajām privātuma saistībām), līdzīgu juridisko pilnvaru draudi gandrīz noteikti izraisīs iekšēju pārskatu par datu saglabāšanas politiku un lobēšanas centieniem skaidrākiem noteikumiem.
Privātuma likumu eksperti prognozē pastiprinātu normatīvo rūpību. Lādē vada Eiropas Savienība ar savu stingro GDPR (vispārējo datu aizsardzības regulējumu) un novatorisko AI likumu (kas AI izstrādātājiem uzliek uz risku balstītu sistēmu). Paredzams, ka citas tautas un reģioni sekos šim piemēram. Tas, iespējams, varētu izraisīt visaptverošākus federālos datu privātuma likumus ASV, kas īpaši attiecas uz AI. Pati juridiskā cīņa, kad federālais tiesnesis, kas jau ļauj galvenajām autortiesību pārkāpumu prasībām, ir paredzēta, lai veidotu AI attiecību nākotni ar intelektuālo īpašumu un lietotāju datiem.
Incidents kalpo kā modināšanas zvans: lai gan AI piedāvā neticamas ērtības, patiesās “bezmaksas” AI atbilžu izmaksas varētu būt saistītas ar mūsu digitālās privātuma un neredzēto krātuvju pamatiem mūsu sarunām. Tā kā AI ir dziļāk integrēta mūsu dzīvē, pieprasījums pēc caurspīdīguma, spēcīga privātuma aizsardzības pasākumi un skaidra izpratne par datu aizturi tikai kļūs skaļāka.