

Google ir pavadījis pēdējo gadu, ieviešot AI modeļus tālruņos, klēpjdatoros un malas ierīcēs. Izaicinājums vienmēr ir bijis viens un tas pats: jaudīgiem multimodālajiem modeļiem parasti ir nepieciešams liels atmiņas apjoms un specializēta aparatūra.
Google DeepMind domā, ka ir atradis veidu, kā apiet šo problēmu.
Gemma 4 12B: mākslīgā intelekta modelis bez kodētāja, kas paredzēts patēriņa klēpjdatoriem
Trešdien uzņēmums izlaida Gemma 4 12B — jaunu atvērtā koda multimodālo modeli, kas nodrošina uzlabotas argumentācijas, kodēšanas, redzes un audio iespējas aparatūrai, kas jau pieder daudziem izstrādātājiem.
“Šodien mēs iepazīstinām ar Gemma 4 12B — mūsu jaunāko modeli, kas izstrādāts, lai nodrošinātu aģentu multimodālu inteliģenci tieši klēpjdatoros. Samazinot plaisu starp mūsu malai draudzīgo E4B un mūsu progresīvāko 26B ekspertu maisījumu (MoE), Gemma 4 12B iepako jaudīgas iespējas. Mūsu modelim ir arī samazināta atmiņa. ievades,” teikts Google emuāra ierakstā.
Izlaidums ir pieejams saskaņā ar Apache 2.0 licenci, sniedzot izstrādātājiem un uzņēmumiem plašu brīvību izmantot, modificēt un komercializēt modeli.
Google arī uzsvēra palaišanu vietnē X, rakstot:
“Iepazīstieties ar Gemma 4 12B! Vienots, bez kodētāja multimodāls modelis, kas izstrādāts, lai nodrošinātu augstas veiktspējas inteliģenci tieši jūsu klēpjdatorā, un tas ir izlaists saskaņā ar Apache 2.0 licenci. Tas mazina plaisu starp malu efektivitāti un uzlabotu spriešanu. Lūk, kas jauns ar Gemma 4 12B.”
Atšķirībā no daudzām modernām multimodālām sistēmām, kas balstās uz atsevišķiem redzes un audio kodētājiem, Gemma 4 12B izmanto citu ceļu. Modelis apstrādā vairākus datu tipus, izmantojot vienotu arhitektūru, samazinot atmiņas apjomu un vienkāršojot izvietošanu.
Izlaidums ir pieejams saskaņā ar Apache 2.0 licenci, sniedzot izstrādātājiem un uzņēmumiem plašu brīvību izmantot, modificēt un komercializēt modeli.
Atšķirīga pieeja multimodālajam AI
Lielākā daļa multimodālo AI sistēmu ir veidotas, balstoties uz vairākiem specializētiem komponentiem. Attēli parasti tiek apstrādāti, izmantojot lielus redzes kodētājus, pirms tie tiek nodoti valodas modelim. Audio iet pa līdzīgu ceļu, izmantojot īpašus runas apstrādes tīklus.
Šī arhitektūra darbojas labi, taču tai ir kompromisi. Papildu komponenti patērē atmiņu, palielina latentumu un palielina inženierijas sarežģītību.
Gemma 4 12B noņem lielu daļu šīs tehnikas.
Attēliem modelis izmanto vieglu 35 miljonu parametru redzes moduli, kas pārvērš attēla ielāpus marķieros un pēc tam ievada tos tieši transformatora mugurkaulā. Audio apstrāde ir vēl racionālāka. Neapstrādāts 16 kHz audio tiek pārveidots tieši modeļa marķiera telpā, neprasot īpašu audio kodētāju.
Rezultāts ir tas, ko DeepMind raksturo kā “multimodālu arhitektūru bez kodētāja”. Teksts, attēli un audio plūst caur vienotu tikai dekodētāja transformatoru, nevis atsevišķiem apstrādes cauruļvadiem.
Modelis ietver Multi-Token Prediction (MTP) izstrādātājus spekulatīvai dekodēšanai, kas var ievērojami palielināt secinājumu izdarīšanas ātrumu.
Gemma 4 12B etaloni: sitiens virs sava svara
Tas, kas padara Gemma 4 12B ievērojamu, ir ne tikai tā arhitektūra, bet arī tas, cik cieši tas atbilst lielākām sistēmām.
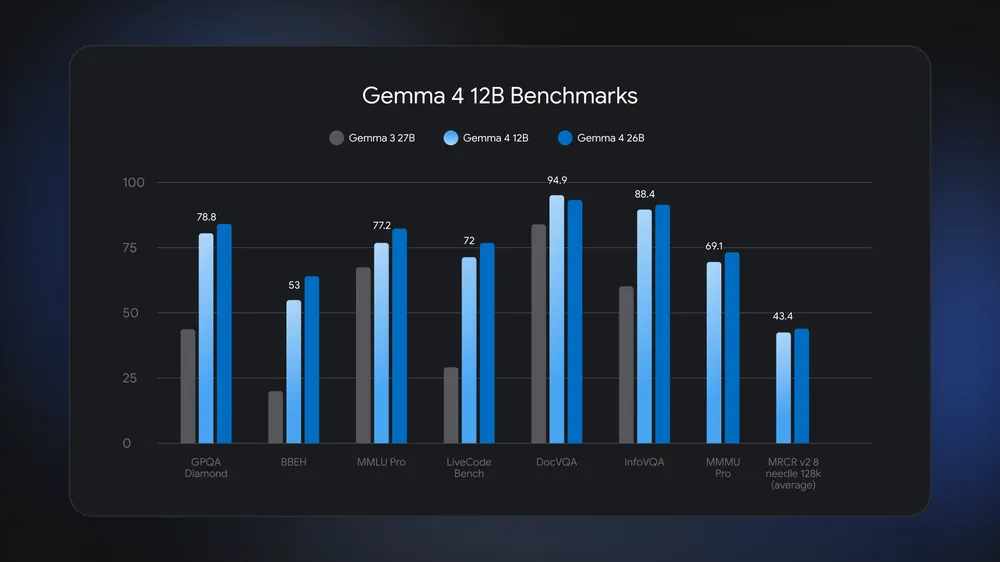
Saskaņā ar etaloniem, kas publicēti kopā ar modeli, Gemma 4 12B nodrošina veiktspēju, kas tuvojas lielākajam Gemma 4 26B ekspertu kombinācijas modelim vairākos argumentācijas un multimodālos uzdevumos, vienlaikus prasa mazāk nekā pusi atmiņas.
Modelis sasniedza 78,8% GPQA Diamond, etalonā, kas koncentrējas uz absolventu līmeņa zinātnes jautājumiem. Tas ieguva 77,2% MMLU Pro un 72% LiveCodeBench v6, kas novērtē reālās pasaules kodēšanas veiktspēju.
Multimodālie kritēriji bija vienlīdz spēcīgi. Gemma 4 12B sasniedza 94,9% DocVQA, 88,4% InfoVQA un 69,1% MMMU Pro. Matemātiskās spriešanas uzdevumos tas publicēja 77,5% AIME 2026 un 79,7% MATH-Vision.
Modelis atbalsta 256 000 marķieru konteksta logu, nodrošinot pietiekamu jaudu, lai apstrādātu garus dokumentus, lielas kodu bāzes, izpētes materiālus un aģentu darbplūsmas, kurām nepieciešams paplašināts pamatojums.
Izstrādāts klēpjdatoriem, ko izstrādātāji jau izmanto
Lielākā daļa DeepMind prezentācijas ir vērsta uz pieejamību.
Lieli AI modeļi bieži liek izstrādātājiem izvēlēties starp mākoņa infrastruktūru un ļoti kvantificētu vietējo izvietošanu. Gemma 4 12B mērķis ir vidusceļš.
Modelis ir optimizēts klēpjdatoriem un galddatoru sistēmām, kas aprīkotas ar aptuveni 16 GB VRAM vai vienotu atmiņu. Tas ietver daudzas modernas Windows iekārtas un Apple MacBook modeļu klāstu.
Agrīnās kopienas pārbaudes ir devušas iepriecinošus rezultātus. Viens izstrādātājs ziņoja, ka RTX 4060 ģenerē aptuveni 21 marķieri sekundē, izmantojot Unsloth dinamisko GGUF kvantēšanu un llama.cpp.
Modelis atbalsta teksta un attēlu ievadi no kastes, ietver vietējās audio iespējas un var apstrādāt rīku izsaukšanu, daudzpakāpju argumentāciju, bezsaistes kodēšanas uzdevumus un vietējā aģenta darbplūsmas.
Atvērtais avots no pirmās dienas
Google izlaiž Gemma 4 12B ekosistēmā, kas pēdējā gada laikā ir ievērojami nobriedusi.
Modeļu svari jau ir pieejami Hugging Face un Kaggle. Atbalsts ir pieejams tiešraidē populārajos secinājumu ietvaros, tostarp llama.cpp, MLX for Apple Silicon, vLLM, LM Studio, SGLang un Unsloth.
Izstrādātāji, kurus interesē pielāgošana, var precīzi noregulēt modeli, izmantojot Hugging Face TRL, Unsloth, Google Colab vai Vertex AI.
Kāpēc šis izlaidums ir svarīgs
AI nozare pēdējos divus gadus ir pavadījusi lielu daļu, meklējot lielākus modeļus, lielākus klasterus un lielākus infrastruktūras budžetus.
Gemma 4 12B norāda citā virzienā.
Modelis parāda, ka uzlabotajām multimodālajām iespējām vairs nav jādzīvo tikai datu centros, kas ir aprīkoti ar dārgiem GPU. DeepMind pieeja bez kodētāja samazina pieskaitāmās izmaksas, samazina aparatūras prasības un padara vietējo izvietošanu praktisku daudz plašākai auditorijai.
Šai maiņai varētu būt ietekme, kas ir daudz plašāka par hobiju projektiem. Uz privātumu orientēti asistenti, bezsaistes kodēšanas rīki, lokālās izguves sistēmas, uzņēmuma zināšanu aģenti un radošās lietojumprogrammas kļūst daudz realizējamākas, ja spējīgi modeļi var darboties tieši patērētāju aparatūrā.
Lielākais stāsts nav par modeļa izmēru, bet gan par to, kur tas var darboties.
Jau gadiem ilgi uzlabotais multimodālais AI lielā mērā ir bijis saistīts ar jaudīgu mākoņa infrastruktūru un dārgiem GPU. Gemma 4 12B liecina, ka starpība samazinās. Apvienojot spēcīgas argumentācijas, kodēšanas, redzes un audio iespējas modelī, kas ērti iederas daudzos mūsdienu klēpjdatoros, Google sola, ka nākamais AI izstrādes vilnis notiks tuvāk lietotājam, nevis tikai datu centrā.
Gemma 4 12B nav lielākais Google modelis. Tas var izrādīties viens no praktiskākajiem.