
Ķīniešu AI starta DeepSeek pieaugums nav bijis nekas ievērojams. Pēc tam, kad bija pārspējis Chatgpt App Store, Deepseek nosūtīja triecienviļņus uz tehnoloģiju pasauli, izraisot tirgū neprātu. Bet visa uzmanība nav bijusi pozitīva. DeepSeek vietne saskārās ar uzbrukumu, kas piespieda uzņēmumu apturēt reģistrāciju, un daži skeptiķi apšaubīja, vai starta uzņēmums ir paļāvies uz eksporta ierobežotajām NVIDIA H100 mikroshēmām, nevis uz H800 mikroshēmām, kuras, kā apgalvoja, izmantojiet, piesaistot bažas par atbilstību un izmaksu efektivitāti.
Tagad Kalifornijas Universitātes Bērklija pētnieku sasniegums izaicina dažus no šiem pieņēmumiem. Komanda, kuru vada Ph.D. Kandidātam Jiayi Pan ir izdevies atkārtot DeepSeek R1-Zero galvenās iespējas par mazāk nekā 30 USD-mazāk nekā nakts izmaksas. Viņu pētījums varētu izraisīt jaunu mazu modeļa RL revolūcijas laikmetu.
Viņu atklājumi liecina, ka izsmalcinātai AI argumentācijai nav jābūt ar milzīgu cenu zīmi, potenciāli mainot līdzsvaru starp AI pētījumiem un pieejamību.
Bērklija pētnieki atjauno Deepseek R1 tikai par 30 USD – izaicinājums H100 stāstījumam
Bērklija komanda saka, ka viņi strādāja ar 3 miljardu parametru valodas modeli no DeepSeek, apmācot to, pastiprinot mācīšanos attīstīt pašpārbaudes un meklēšanas spējas. Mērķis bija atrisināt aritmētiskus izaicinājumus, sasniedzot mērķa numuru-eksperimentu, kuru viņiem izdevās pabeigt tikai par 30 USD. Salīdzinājumam-Openai O1 API maksāja 15 USD par miljonu ievades žetonu-vairāk nekā 27 reizes lielāku par DeepSeek-R1 cenu, kuras cena ir tikai USD 0,55 par miljonu žetonu. PAN uzskata šo projektu kā soli, lai samazinātu barjeru pastiprināšanas apguves mērogošanas pētījumiem, īpaši ņemot vērā tā minimālās izmaksas.
Bet ne visi atrodas uz kuģa. Mašīnmācības eksperts Nātans Lamberts apšauba Deepseek apgalvojumu, ka 671 miljardu parametru modeļa apmācība maksā tikai 5 miljonus USD. Viņš apgalvo, ka šis skaitlis, iespējams, izslēdz tādus galvenos izdevumus kā pētniecības personāls, infrastruktūra un elektrība. Viņa aplēsēs DeepSeek AI gada darbības izmaksas ir no 500 miljoniem USD līdz vairāk nekā 1 miljardu USD. Pat ja tā, sasniegums izceļas – it īpaši ņemot vērā, ka augstākās ASV AI firmas gadā ieliek USD 10 miljardus gadā.
Eksperimenta sadalīšana: mazi modeļi, liela ietekme
Saskaņā ar Jiayi Pan ziņu par Nitter, komanda veiksmīgi reproducēja DeepSeek R1-Zero, izmantojot nelielu valodas modeli ar 3 miljardiem parametru. Sākot pastiprināšanas mācīšanos atpakaļskaitīšanas spēlē, modelis izstrādāja pašpārbaudes un meklēšanas stratēģijas-spējas uzlabotās AI sistēmās.
Galvenie paņēmieni no viņu darba:
- Viņi veiksmīgi reproducēja DeepSeek R1-Zero metodes par zem 30 USD.
- Viņu 1,5 miljardu parametru modelis parādīja progresīvas spriešanas prasmes.
- Veiktspēja bija līdzvērtīga lielākām AI sistēmām.
“Countdown spēlē mēs reproducējām DeepSeek R1-Zero, un tas vienkārši darbojas. Izmantojot RL, 3B bāzes LM attīsta pašpārbaudes un meklēšanas spējas patstāvīgi. Jūs varat izjust Ahah mirkli pats par
Mēs reproducējām DeepSeek R1-Zero atpakaļskaitīšanas spēlē, un tas vienkārši darbojas
Izmantojot RL, 3B bāzes LM izstrādā pašpārbaudes un meklēšanas spējas vieni par sevi
Jūs varat izjust Ahah brīdi pats par kodu: https://t.co/b2isn1prxv
Lūk, ko mēs uzzinājām 🧵 pic.twitter.com/43bvymms8x
– Jiayi Pan (@Jiayi_pirate) 2025. gada 24. janvāris
Pastiprināšanas mācīšanās izrāviens
Pētnieki sāka ar bāzes valodas modeli, strukturētu uzvedni un zemes patiesības atlīdzību. Pēc tam viņi iepazīstināja ar pastiprināšanas mācīšanos Atpakaļskaitīšanauz loģiku balstīta spēle, kas pielāgota no Lielbritānijas TV šova. Šajā izaicinājumā spēlētājiem jāsasniedz mērķa numurs, izmantojot aritmētiskās operācijas – iestatīšana, kas mudina AI modeļus uzlabot viņu spriešanas prasmes.
Sākotnēji AI radīja nejaušas atbildes. Izmantojot izmēģinājumu un kļūdu, tas sāka pārbaudīt savas atbildes, pielāgojot savu pieeju ar katru iterāciju – atspoguļojot to, kā cilvēki risina problēmas. Pat mazākais 0,5 miljardu parametru modelis varēja tikai veikt vienkāršus minējumus, bet, ja tas ir samazināts līdz 1,5 miljardiem un pēc tam, AI sāka demonstrēt progresīvāku argumentāciju.
“Countdown spēlē mēs reproducējām DeepSeek R1-Zero, un tas vienkārši darbojas. Izmantojot RL, 3B bāzes LM attīsta pašpārbaudes un meklēšanas spējas pats par sevi, jūs varat izjust Ahah mirkli pats par
https://github.com/Jiayi-pan/tinyzero
Lūk, ko mēs uzzinājām, ”Pans sacīja amatā par Nitter

Pārsteidzoši atklājumi
Viens no interesantākajiem atklājumiem bija tas, kā dažādi uzdevumi lika modelim izstrādāt atšķirīgas problēmu risināšanas metodes. Iekšā Atpakaļskaitīšanatā uzlaboja meklēšanas un verifikācijas stratēģijas, iemācoties atkārtot un uzlabot atbildes. Risinot reizināšanas problēmas, tas piemēroja sadales likumu – samazinot skaitļus līdzīgi kā cilvēki, garīgi risinot sarežģītus aprēķinus.
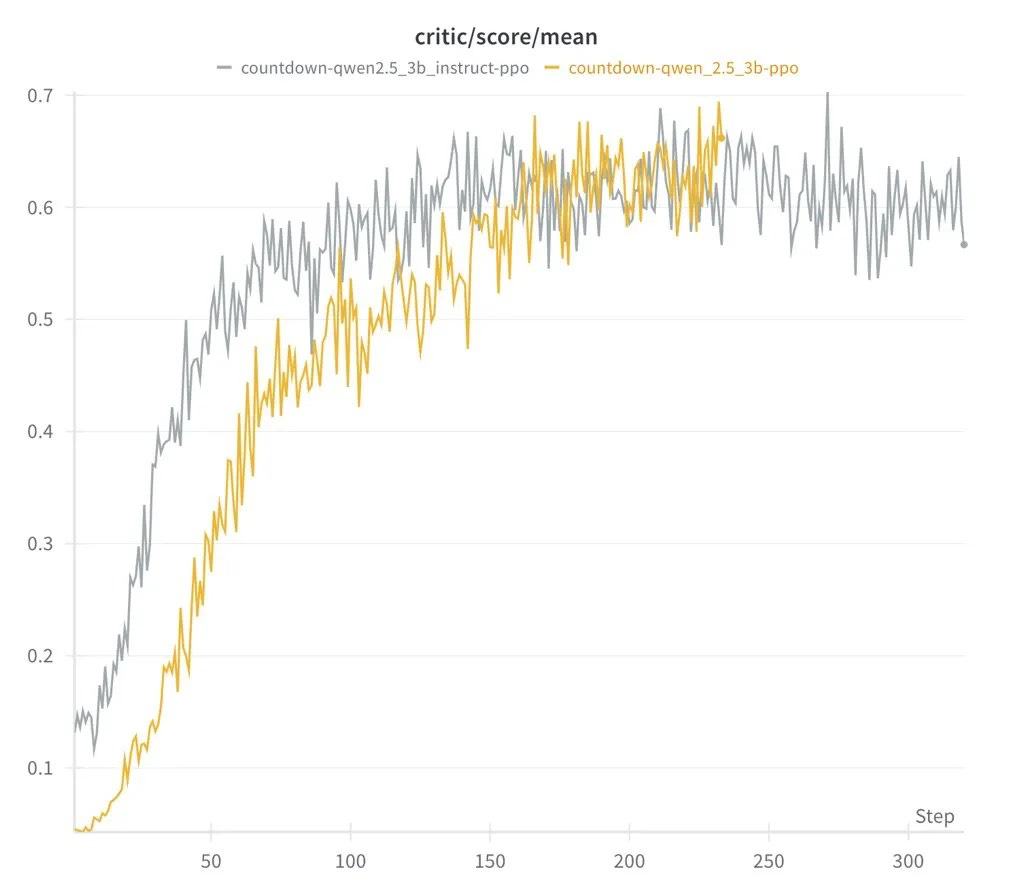
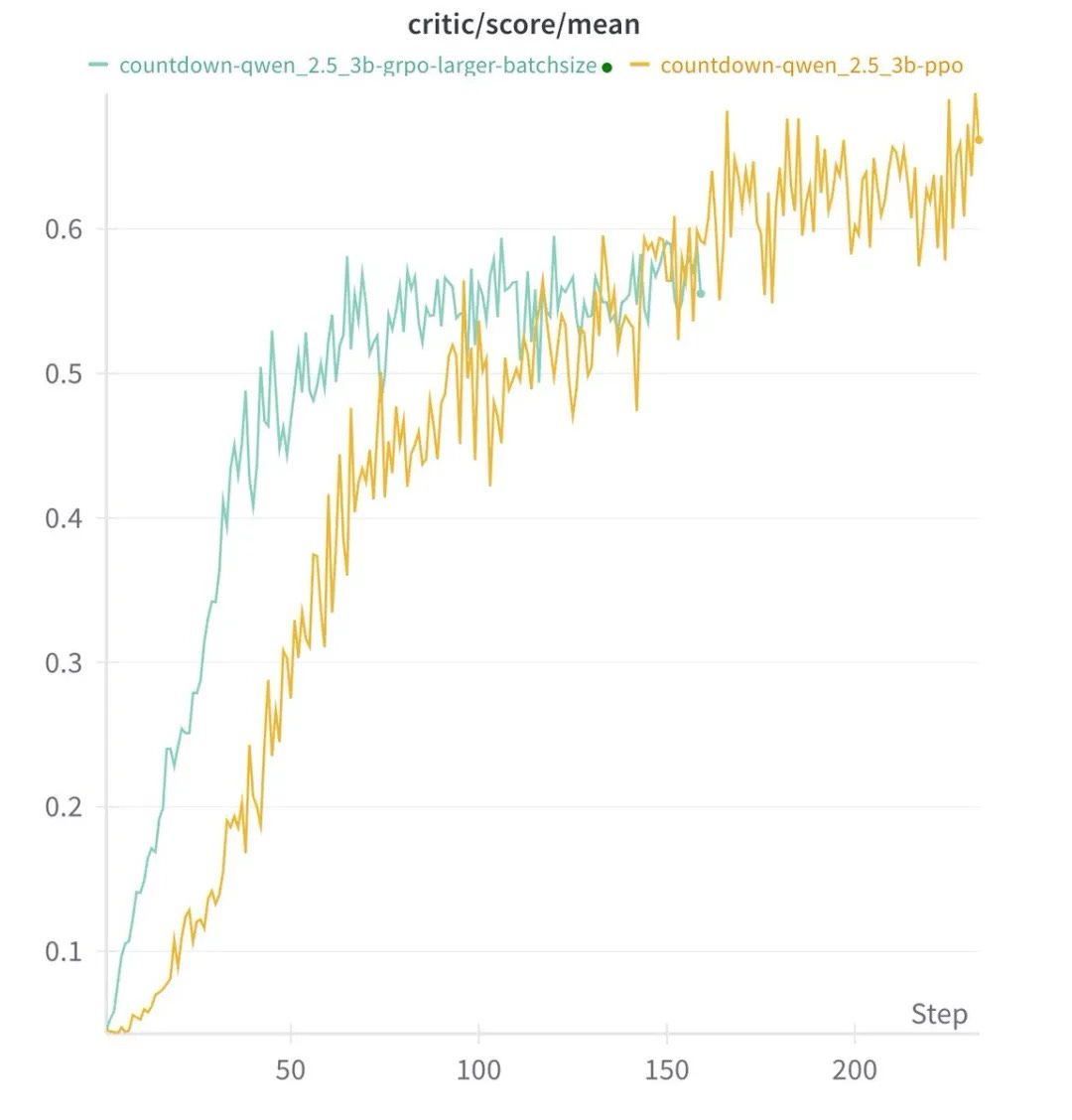
Vēl viens ievērojams secinājums bija tas, ka pastiprināšanas mācīšanās algoritma izvēle – neatkarīgi no tā, vai PPO, GRPO vai Prime – bija maza ietekme uz vispārējo sniegumu. Rezultāti bija konsekventi dažādās metodēs, kas liecina, ka strukturētai mācīšanās un modeļa lielumam ir lielāka loma AI iespēju veidošanā nekā konkrētais izmantotais algoritms. Tas izaicina priekšstatu, ka sarežģītai AI nepieciešami milzīgi skaitļošanas resursi, parādot, ka sarežģīta argumentācija var rasties no efektīvām apmācības metodēm un labi strukturētiem modeļiem.
Galvenais pētījums bija tas, kā modelis pielāgoja tās problēmu risināšanas paņēmienus, pamatojoties uz konkrēto uzdevumu.
Gudrāka AI, izmantojot uzdevumam specifisku mācīšanos
Viens no visinteresantākajiem pārņēmumiem ir tas, kā AI pielāgojās dažādiem izaicinājumiem. Countdown spēlei modelis iemācījās meklēšanas un pašpārbaudes paņēmienus. Pārbaudot ar reizināšanas problēmām, tas tām tuvojās atšķirīgi – izmantojot sadales likumu, lai sadalītu aprēķinus pirms to soli pa solim.
Tā vietā, lai akli uzminētu, AI uzlaboja savu pieeju vairākām iterācijām, pārbaudot un pārskatot savas atbildes, līdz tā piezemējās uz pareizā risinājuma. Tas liek domāt, ka modeļi var attīstīt specializētas prasmes atkarībā no uzdevuma, nevis paļauties uz visu piemērotu spriešanas metodi.
AI pieejamības maiņa
Tā kā pilns projekts maksā mazāk nekā 30 USD un kods, kas publiski pieejams vietnē GitHub, šis pētījums padara Advanced AI pieejamāku plašākam izstrādātāju un pētnieku lokam. Tas izaicina priekšstatu, ka revolucionārais progress prasa miljardu dolāru budžetus, pastiprinot domu, ka viedā inženierija bieži var pārspēt brutālu spēku izdevumus.
Šis darbs atspoguļo redzējumu, kuru ilgi aizstāvēja Ričards Suttons, vadošais pastiprināšanas mācīšanās figūra, kurš apgalvoja, ka vienkāršie mācību ietvari var dot spēcīgus rezultātus. Bērklija komandas atklājumi liecina, ka viņam bija taisnība-Complex AI iespējām nav obligāti nepieciešama masīva mēroga skaitļošana, tikai pareiza apmācības vide.
