

AI sacīkstes vairs nav tikai gudrāku modeļu veidošana. Tās kļūst par sacīkstēm, lai padarītu šos modeļus lētākus un ātrāk darbināmus.
Ķīniešu mākslīgā intelekta starta uzņēmums DeepSeek ir ieviesis DSpark — jaunu secinājumu sistēmu, kas, pēc tā teiktā, var sniegt atbildes līdz pat 85% ātrāk. Ja šie ieguvumi saglabāsies ražošanā, šī tehnoloģija ļautu AI pakalpojumu sniedzējiem apkalpot daudz vairāk lietotāju ar tādu pašu aparatūru, samazinot vienas no nozares augstākajām ekspluatācijas izmaksām laikā, kad pieprasījums pēc GPU joprojām pārsniedz piedāvājumu.
Izlaidums iezīmē DeepSeek jaunāko centienu uzlabot AI efektivitāti, nevis modeļa izmēru. Tas notiek, kad Ķīnas AI uzņēmumi novirza savu uzmanību no lielāku pamatu modeļu apmācības uz secinājumu izmaksu samazināšanu, joma kļūst arvien svarīgāka uzņēmumu izvietošanai un patērētāju AI pakalpojumiem.
DeepSeek’s DSpark
Sestdien vietnē GitHub publicētajā rakstā DeepSeek sīki izklāstīja DSpark pētījumu. Uzņēmums norādīja, ka sistēma risina vienu no lielākajām AI apkalpošanas vājajām vietām: lēno, pa vienam marķiera ģenerēšanas procesu, ko izmanto mūsdienu lielie valodu modeļi. Garas atbildes bieži atstāj GPU gaidīšanu starp aprēķiniem, samazinot aparatūras izmantošanu un palielinot lietotāju reakcijas laiku.
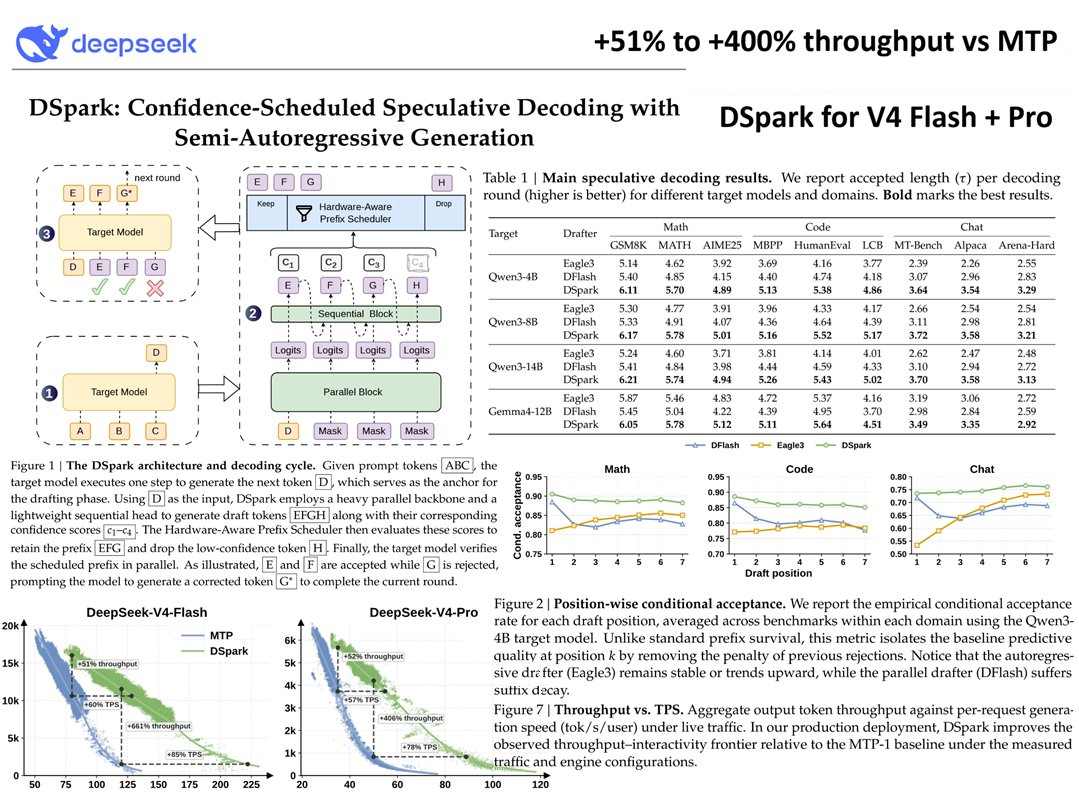
“Mēs ieviešam DSpark — spekulatīvu dekodēšanas sistēmu, kas apvieno lielas caurlaidības paralēlo ģenerēšanu ar adaptīvu, slodzes apzinīgu verifikāciju,” raksta DeepSeek.
Lai atrisinātu šo problēmu, DeepSeek izveidoja DSpark, izmantojot spekulatīvu dekodēšanas sistēmu. Tā vietā, lai secīgi ģenerētu un pārbaudītu katru marķieri, sistēma izmanto vieglu uzmetuma modeli, lai prognozētu kandidātu atbildes, pirms tās tiek nodotas lielākam modelim partijas verifikācijai. Šī pieeja ļauj paralēli pabeigt vairāk darba, samazinot latentumu, neprasot lielākas skaitļošanas kopas.
DSpark iet soli tālāk, izmantojot daļēji autoregresīvu ģenerēšanas metodi, kas rada nelielas marķieru grupas, nevis ģenerē katru marķieri atsevišķi. Ietvars ietver uz ticamību balstītu plānošanas sistēmu, kas dinamiski pielāgo verifikāciju, pamatojoties uz skaitļošanas pieprasījumu. Mazākas darba slodzes periodos sistēma veic vairāk verifikācijas, lai maksimāli palielinātu GPU izmantošanu. Maksimālā pieprasījuma laikā tas samazina verifikācijas biežumu, lai nodrošinātu ātru atbildes plūsmu.
Saskaņā ar DeepSeek teikto, rezultāts ir reakcijas ģenerēšanas ātrums, kas uzlabojas līdz pat 85%.
“DeepSeek, pieņemot to, ko tā sauca par spekulatīvo dekodēšanas sistēmu, DSpark teica, ka tas palielināja katra lietotāja atbildes ātrumu līdz pat 85 procentiem, kas ir efektivitātes pieaugums, kas varētu samazināt AI sistēmu atkarību no lielākas, jaudīgākas mikroshēmu infrastruktūras,” ziņoja The China Morning Post.
DeepSeek jaunākais laidiens ir vērsts uz vienu no AI dārgākajiem sastrēgumiem
Ietekme pārsniedz ātrumu. Huang Yong, Pekinā bāzētais programmētājs, teica, ka augstāka secinājumu efektivitāte varētu ievērojami samazināt skaitļošanas infrastruktūras apjomu, kas nepieciešams AI lietojumprogrammu apkalpošanai. Praktiski runājot, GPU, kas iepriekš apstrādāja aptuveni 100 lietotāju pieprasījumus, pēc uzlabojuma varētu apstrādāt aptuveni 185 pieprasījumus, pieņemot līdzīgu darba slodzi.
Darbs tiek veikts, jo AI uzņēmumi saskaras ar pieaugošām infrastruktūras izmaksām visā pasaulē. Pieaugušo modeļu apmācība joprojām piesaista virsrakstus, tomēr šo modeļu apkalpošana miljoniem lietotāju ir kļuvusi par vienu no lielākajiem periodiskajiem izdevumiem AI pakalpojumu sniedzējiem. Katrs secinājumu efektivitātes pieaugums samazina aparatūras prasības, elektroenerģijas patēriņu un darbības izmaksas.
Laiks ir īpaši nozīmīgs DeepSeek. Uzņēmums turpina darboties saskaņā ar ASV eksporta ierobežojumiem, kas ierobežo Ķīnas piekļuvi vismodernākajām AI mikroshēmām. Programmatūras efektivitātes uzlabošana piedāvā vienu ceļu konkurētspējīgas veiktspējas nodrošināšanai, nepaļaujoties tikai uz jaunāko aparatūru.
DeepSeek pārbaudīja DSpark vairākos atvērtā pirmkoda modeļos, tostarp Google DeepMind Gemma un Alibaba Qwen saimē. Rezultāti liecina, ka sistēma varētu pārsniegt DeepSeek modeļus un sniegt labumu izstrādātājiem, kuri meklē ātrākus secinājumus bez lieliem infrastruktūras ieguldījumiem.
Uzņēmums ir izlaidis gan pētījumu, gan DSpark ieviešanu kā atvērtā pirmkoda, izmantojot GitHub un Hugging Face. Projekts tapis sadarbībā ar Pekinas Universitāti.
Nākamais AI karš nav saistīts ar modeļu apmācību. Tas viņus apkalpo ātrāk un lētāk.
Paziņojums nāk, kad secinājumu optimizācija kļūst par vienu no AI visciešāk novērotajiem kaujas laukiem. Ķīnas tehnoloģiju uzņēmumi cīnās, lai samazinātu apkalpošanas izmaksas, jo AI ieviešana uzņēmumos un patērētāju lietojumprogrammās paātrinās.
Tencent uzsvēra to pašu izaicinājumu piektdien, aprakstot secinājumu efektivitāti kā galveno šķērsli lielu AI modeļu izvietošanai mazāk spējīgā aparatūrā. Uzņēmums paziņoja, ka ir ieguldījis lielus ieguldījumus inženiertehniskajās tehnikās, tostarp uzmanības optimizēšanā, asinhronā skaitļošanas komunikācijā un atmiņas kešatmiņā, lai palielinātu izvades ātrumu.
Xiaomi sasniedza līdzīgu pagrieziena punktu šā mēneša sākumā. Tās AI komanda teica, ka uzņēmuma MiMo-V2.5-Pro-UltraSpeed modelis var ģenerēt vairāk nekā 1000 marķieru sekundē, padarot to par vienu no ātrākajām publiski paziņotajām AI secinājumu sistēmām.
Pēdējo divu gadu laikā saruna koncentrējās uz to, kurš varētu izveidot visspējīgāko AI modeli. DSpark izvirza citu jautājumu, kas varētu veidot nozares nākamo posmu: kurš var nodrošināt augstas veiktspējas AI par viszemākajām izmaksām?