
Šobrīd mēs jau zinām, ka AI modeļiem ir jāapgūst daudz datu no daudziem avotiem, lai mācītos. Uzņēmumi iegūst datus no tādiem avotiem visā internetā kā e-grāmatas, sociālo mediju vietnes, video vietnes, ziņu vietnes, emuāri utt. Liela daļa datu ir sabiedrībai bez maksas, taču AI uzņēmumi arī ņem daudz datu no augstākās kvalitātes avotiem. Mēs runājam par maksas saturu, kas aizsargāts ar autortiesībām. Tas var nebūt daudz nozīmē vidusmēra cilvēkam, bet kāda ir šīs prakses ietekme un vai tā ir pamatota?
Mūsdienās mēs redzam pārmaiņas nozarē. Lieli ziņu un mediju uzņēmumi paraksta darījumus, kas nodod savu saturu AI uzņēmumiem, piemēram, OpenAI un Meta. Tas patiešām šokēja masas, jo AI tehnoloģijai ir bijusi negatīva ietekme uz žurnālistiku. Tāpēc ir nedaudz pārsteidzoši, ka tik daudz ziņu kompāniju ar prieku apkalpo savu saturu AI uzņēmumiem, lai žurnālisti vēl vairāk kļūtu novecojuši.
Juridiskā puse
Cita starpā šī prakse ir saistīta ar izvairīšanos no juridiskām problēmām ar uzņēmumiem. Neilgi pēc AI sprādziena mēs noskaidrojām, kur AI uzņēmumi ieguva datus, lai apmācītu savus AI modeļus. Vairākām lielākajām kompānijām nepatika, ka AI uzņēmumi skrāpēja savu saturu, un viens no galvenajiem uzņēmumiem bija The New York Times. Šī raksta rakstīšanas laikā The New York Times ir iesaistīts milzīgā juridiskā cīņā ar OpenAI. Šis uzņēmums nokasīja daudzus The New York Times ar autortiesībām aizsargātus rakstus. Ne tikai tas, bet arī New York Times apgalvo, ka ChatGPT burtiski atkārto savu rakstu sadaļas.
Citas līdzīgas tiesas prāvas pēdējā gada laikā ir parādījušās, un mēs sagaidām vairāk no dažādiem uzņēmumiem. Tas jo īpaši attiecas uz to, ka mēs redzam arvien vairāk stāstu, kas atklāj, cik daudz augstākās kvalitātes satura AI uzņēmumi izmantoja, lai apmācītu savus modeļus. Cilvēki atskatās uz datu kopām, kuras izmantoja daži no lielākajiem AI modeļiem, ko izmantoja, lai apmācītu, un viņi redz, ka liela daļa satura nāk no maksas vietnēm.
Analīze
Kā minēts, tiek publicēti ziņojumi, kas atklāj, cik daudz augstākās kvalitātes un maksas datu AI uzņēmumi vāc, lai apmācītu savus AI modeļus. News Media Alliance pagājušajā gadā publicēja ziņojumu, ļaujot mums zināt, ka dažas no lielākajām datu kopām pasaulē izmantoja ievērojamu daudzumu augstākās kvalitātes satura.
Tika konstatēts, ka OpenWebText, datu kopas, ko izmantoja OpenAI GPT-2 modeļa apmācīšanai, sastāvēja no aptuveni 10% augstākās kvalitātes satura. Tas var neizklausīties daudz, taču šajā datu kopā ir aptuveni 23 miljoni tīmekļa lapu. Tātad 10% no 23 miljonu lappušu pīrāga ir liela šķēle. Ne tikai tas, bet arī nav pārāk daudz augstākās kvalitātes ziņu vietņu, salīdzinot ar internetu kopumā, tāpēc jebkura procentuālā daļa, kas pārsniedz 0,001%, ir ievērojama.
Ko tas nozīmē? Tas nozīmē, ka tādi uzņēmumi kā OpenAI ne tikai pārmeklē internetu un nedod saviem modeļiem to, kas parādās. AI uzņēmumi saviem modeļiem bieži izmanto datus no augstākās kvalitātes vietnēm.
Kā mēs to zinām?
Iepriekš minētais ziņojums pavēra durvis vairākām ziņām. Nesenā Zifa Deivisa analīze norādīja uz kaut ko līdzīgu; datu kopas, ko izmanto galveno modeļu apmācīšanai, sastāv no liela apjoma maksas satura satura. Tomēr Ziff Davis ziņojumā ir ņemtas vērā četras datu kopas, un tas atklāj kaut ko par AI uzņēmumu nodomiem.
Četras datu kopas, ko tas ņem vērā, ir Common Crawl, C4, OpenWebText un OpenWebText2. Vairāki AI uzņēmumi izmanto šīs četras datu kopas, lai apmācītu savus modeļus.
Common Crawl tika izmantots, lai apmācītu OpenAI GPT-3 un Meta LLaMA. C4 tika izmantots, lai apmācītu Google LaMDA un T5 modeļus kopā ar LLaMA. OpenWebText tika izmantots, lai apmācītu GPT-2, un OpenWebText2 tika izmantots GPT-3 apmācīšanai. Visticamāk, šīs datu kopas tika izmantotas citos galvenajos modeļos, taču iepriekš minētie modeļi tika iekļauti pārskatā.
Tātad šīs datu kopas apmācīja dažus diezgan lielus modeļus. Acīmredzot tie ir diezgan novecojuši. OpenAI pašlaik ir vairākas iterācijas savā GPT-4 sērijā, un Meta ir LLaMA 3, tāpēc iepriekš uzskaitītie modeļi ir krietni pārsnieguši savu izcilību. Tomēr mums nevajadzētu šķaudīt par milzīgo datu apjomu, kas pastāv šajās datu kopās. OpenWebText2 satur vairāk nekā 17 miljonus tīmekļa lapu, savukārt OpenWebText 2 satur 23 miljonus tīmekļa lapu. C4 paceļas virs tiem ar 365 miljoniem tīmekļa lapu, bet dominējošais čempions ir Common Crawl ar 3,15 miljardu tīmekļa lapu apmēru.
Raugoties pēc skaitļiem, šķiet, ka GPT-3 un LLaMA vajadzētu būt gudrākajiem modeļiem sarakstā. Tomēr var būt arī otrādi.
Datu kopas kopšana
Kad jūs mācāties skolā, jūsu skolotājs ne tikai stāv jūsu priekšā un sešas stundas pēc kārtas nerunā par patvaļīgiem faktiem. Informācija, ko viņi jums sniedz, ir jāapkopo skolotājam, skolai un skolas padomei. Tāpēc jums ir stundu plāni un standarta mācību programma. Kāds tam sakars ar AI modeļiem? AI modeļi ir vairāk kā cilvēki, nekā jūs domājat.
Ja esat mākslīgā intelekta modelis un jums tiek ievadīta datu kopa, jūs vēlētos saņemt augstas kvalitātes un atbilstošu informāciju. Tādējādi uzņēmumi ne vienmēr papildina savus modeļus ar nejaušiem datiem. Datu kopas dažreiz tiek tīrītas un atlasītas. Datu kopas tīrīšana ir process, kas novērš datu dublikātus, kļūdas, nekonsekventu informāciju, nepilnīgus datus un daudz ko citu. Savā ziņā tas apgriež taukus. Datu kopas pārraudzība organizē datu kopu, lai padarītu informāciju pieejamāku. Tie ir pārāk vienkāršoti, taču jūs varat lasīt vairāk, izmantojot hipersaites.
Jebkurā gadījumā datu kopu tīrīšana un pārzināšana pamatā apstrādā datus un izvērš tos, lai modelim būtu vieglāk uztvert. Tas ir līdzīgs tam, kā jūsu skolas mācību programma ir organizēta, lai gadu gaitā pakāpeniski pieaugtu grūtības.
Tagad parunāsim par domēna iestādi
Laiks nelielai, tomēr nepieciešamai pieskarei. Šim ziņojumam ir vēl viens aspekts, un viens ir domēna autoritāte. Savā ziņā, jo augstāka domēna autoritāte ir vietnei, jo vietne ir uzticamāka un cienīgāka. Tātad jūs varētu sagaidīt, ka vietnei, piemēram, The New York Times, lielai ziņu korporācijai, ir augstāka domēna autoritāte nekā pavisam jaunai ziņu vietnei, kas katru dienu saņem ne vairāk kā 10 skatījumus.
Ziņojumā tika ņemti vērā 15 ziņu uzņēmumi ar visaugstāko domēna autoritāti. Šis saraksts sastāv no “Advance (Condé Nast, Advance Local), Alden Global Capital (Tribune Publishing, MediaNews Group), Axel Springer, Bustle Digital Group, Buzzfeed, Inc., Future plc, Gannett, Hearst, IAC (Dotdash Meredith un citas nodaļas), News Corp. , The New York Times Company, Penske Media Corporation, Vox Media, The Washington Post un Ziff Davis”.
Ziņojumā domēna autoritāte ir noteikta 1–100 punktu sistēmā. 100 nozīmē, ka vietnei ir vislielākā domēna autoritāte. Iepriekš minētajā sarakstā ir vietnes ar diezgan augstām domēna autoritātēm.
Skaitļi
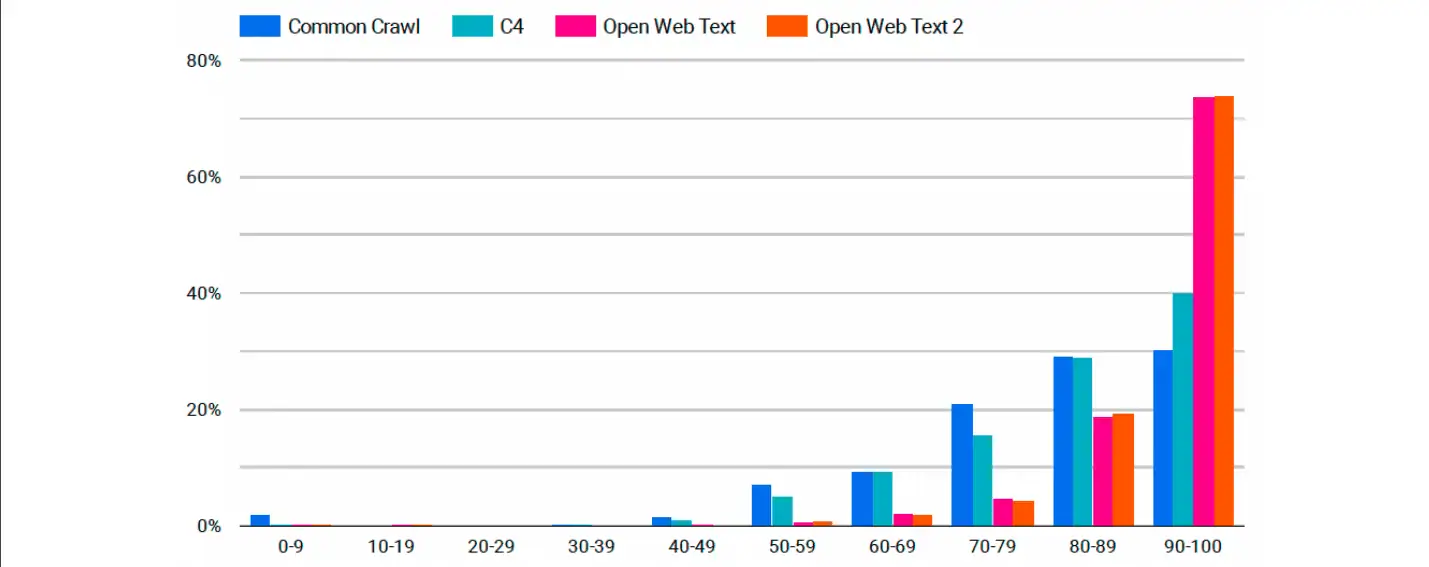
Kāds tam sakars ar datu kopām un AI modeļiem? Nu, saliksim to visu kopā. Pārskatā redzams četru datu kopu sadalījums. Zemāk esošajā diagrammā mēs redzam interesantu tendenci.
Diagrammas X ass parāda domēna autoritātes punktus, kas sadalīti 10 punktu intervālos, un Y ass parāda procentuālo daļu no datu apjoma katrā kopā. Tas parāda, ka nedaudz vairāk nekā 50% Common Crawl vietņu domēna autoritātes rādītāji ir no 0 līdz 9. Tas strauji samazinās, palielinoties domēna autoritātei. Mazāk nekā 10% datu kopas rezultāts ir lielāks par 10 punktiem, un tas turpinās arī pārējā diagrammas daļā.
Pārejot uz C4, rezultāti nav daudz labāki. Apmēram 20% vietņu domēna vērtējums ir no 10 līdz 20 punktiem. Pēc tam tas arī ievērojami samazinās. C4 ir nemainīgi augstāks par Common Crawl lielākajā daļā diagrammas.
Tomēr mēs redzam dramatiskas izmaiņas, kad aplūkojam divas OpenWebText datu kopas. Patiesībā mēs redzam tieši pretējo! Abi modeļi sākas no līdzīgas vietas diagrammā ar rādītājiem no 0 līdz 9, taču tie nepārtraukti pieaug, palielinoties domēna autoritātes rādītājiem. Vairāk nekā 30% OpenWebTexts datu tika iegūti no vietnēm ar domēna autoritātes rādītājiem no 90 līdz 100. Kas attiecas uz OpenWebText 2, aptuveni 40% no šīs datu kopas veido vietnes ar domēna autoritātes rādītājiem no 90 līdz 100.
Tikai augstākās kvalitātes vietnes
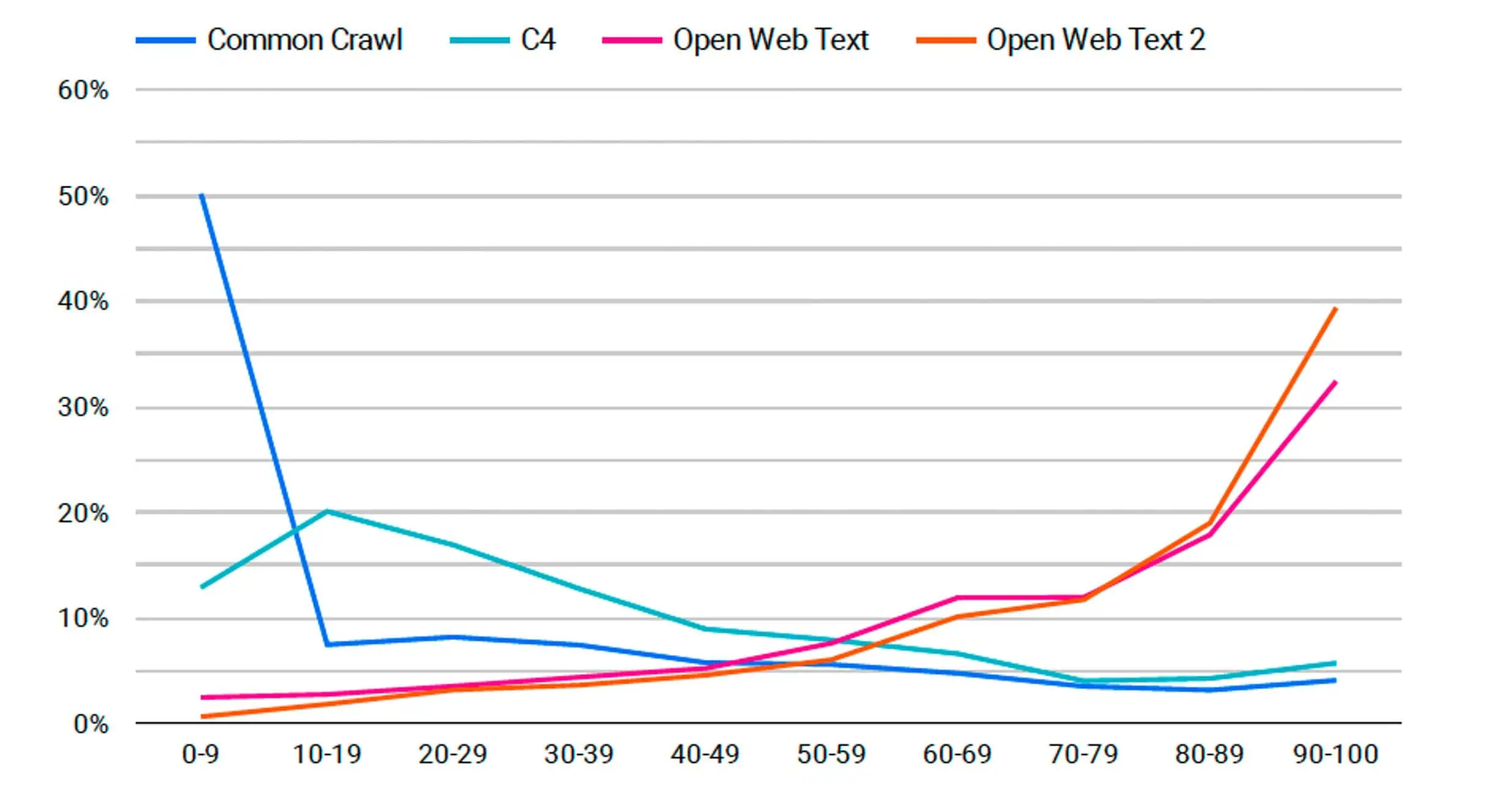
Šeit ir diagramma, kurā parādīti līdzīgi dati. Tomēr visu vietņu datu vietā tiek rādīti dati tikai no iepriekšminētajām augstākās kvalitātes vietnēm.
Zemāk ir diagramma, kurā parādīta katra no iepriekšminētajām publikācijām un to izmantošanas apjoms katrā datu kopā. Mēs redzam, ka abu OpenWebText modeļu procentuālā daļa strauji pieaug, taču šajos divos modeļos ir ievērojami mazāk datu, tāpēc vienam avotam ir vieglāk izveidot lielāku procentuālo daļu.
Lūk, šokētājs
Tātad, mēs redzam, ka OpenWebText datu kopās ir vairāk augstas kvalitātes vietņu datu, taču šeit ir slikts. Atcerieties, kā mēs runājām par datu kopu tīrīšanu un pārvaldību? Šis process ņem neapstrādātus un nefiltrētus datus un apstrādā tos. Pārskatā Common Crawl un C4 nav tīrīti vai atlasīti. Divas OpenWebText datu kopas bija. Tas nozīmē, ka datu kopas ar lielāku augstākās kvalitātes satura apjomu ir tās, kuras ir skārušas cilvēku rokas.
Tas norāda uz to, ka AI uzņēmumi īpaši mērķtiecīgi nolasa augstākās kvalitātes datus. Līdz šim brīdim mēs uzskatījām, ka šie uzņēmumi nolēma vienkārši pārmeklēt vietnes un savos modeļos ievietot pēc iespējas vairāk datu, nepievēršot uzmanību tam, no kurienes tie nāk. Tomēr realitāte ir tāda, ka daudzi no šiem uzņēmumiem, iespējams, īpaši meklē saturu, kuru tiem nevajadzētu izmantot.
Šis pārskats parāda, ka liela daļa OpenAI modeļu apmācībai izmantotā satura ir saistīts ar maksas sienas saturu. Tātad, jautājums ir, cik daudz citu datu kopu tiek apstrādātas, lai sniegtu priekšroku augstākās kvalitātes datiem?
Vai AI uzņēmumi, kas izmanto augstākās kvalitātes datus, ir attaisnojami?
Virspusēji šķiet, ka uzņēmumi ir nepareizi, bet, iedziļinoties, robeža starp labo un nepareizo sāk izplūst. Mēs zinām par juridiskajām sekām. AI uzņēmumi pārkāpj savas robežas, apmācot savus modeļus, izmantojot materiālus ar maksas sienām. Dažos gadījumos šie uzņēmumi ne tikai reproducē maksas satura fragmentus burtiski, bet arī zog datus, lai apmācītu modeļus, kas šos uzņēmumus likvidēs. Tas ir diezgan sajaukts.
Tomēr šai sarunai ir divas puses. Fakts ir tāds, ka AI modeļi ir šeit, un neviens nevar neko darīt lietas labā. Viņi sniedz atbildes uz mūsu jautājumiem, māca mūs utt. Ne tikai tas, bet arī šie AI rīki ir gatavi lietošanai dažās diezgan svarīgās jomās, kurās trūkst darbinieku, piemēram, medicīnā un izglītībā. Ja viņi tiks apmācīti par saturu no interneta, vislabāk viņiem būtu apmācīt augstas kvalitātes saturu.
Lai gan ir grūti atzīt, ka šai praksei varētu būt kāds nopelns, AI kaut kādā veidā skars arvien vairāk mūsu dzīves. Godīgi sakot, labāk būtu izmantot modeļus, kas apmācīti uz augstas kvalitātes datiem, nevis modeļus, kas apmācīti neatkarīgi no tā. Lielai daļai iedzīvotāju nepatīk AI gājiens, taču neviens nevar apturēt progresu. AI pārņems vadību, tāpēc modeļu apmācība augstākas kvalitātes saturam var būt mazākais no diviem ļaunumiem.
Vai tomēr ar to pietiek?
Vai tas attaisno maksas satura izmantošanu? Viena no sliktākajām lietām jebkurā nozarē ir tad, kad liels uzņēmums var vienkārši rīkoties, kā vēlas. Vai jūs uzticētos savam 8 gadus vecajam bērnam vienam neapsargātā konfekšu veikalā? Acīmredzot, ja tuvumā nav darbinieku, kas viņus atturētu no cūcības, jūsu bērns atgriezīsies mājās ar vēdera sāpēm.
Attaisnot uzņēmumus, kuri slēpti izmanto maksājumus, būtībā dod viņiem brīvību, lai iegūtu pēc iespējas vairāk datu, līdzīgi kā bērnam. Būtībā tas viņiem piešķir zāles caurlaidi, lai brīvi iegūtu datus no citiem maksas pakalpojumiem. Uzņēmumiem, kas darbojas internetā, diemžēl ir jādzīvo saskaņā ar interneta noteikumiem; 1. noteikums ir tāds, ka visās vietnēs tiek veikta rāpuļprogramma, un ikviens to var izdarīt ļoti maz.
Zifa Deivisa un News Media Alliance ziņojumi liecina, ka vairāki AI uzņēmumi apzināti izsūkuši datus no augstākās kvalitātes publikācijām un to neatzina. Uzņēmumi iesniedz tiesas prāvas, kā tas pareizi jādara, jo nav iespējams pateikt, cik daudz viņu datu atrodas tajos pašos tērzēšanas robotos, kas zog žurnālistu darbus.